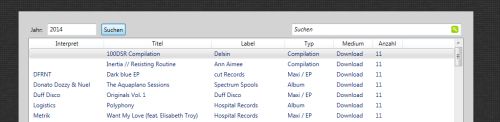
Mit meiner letzten Version habe ich es ermöglicht, dass ich die Charts nicht nur eines Jahres anzeigen kann. Dabei fiel mir auf, dass ich seit 2004 meine Charts bei Jahreswechsel auf die Platte gedumpt habe. Dort standen dann mit Komma getrennt, Interpret, Titel und die Anzahl, wie oft die Platte gespielt wurde, drin. Und da wurde mir klar, dass man beides gut miteinander kombinieren kann.
Also begann der lange, steinige Weg zur Version 4.4. Erstmal habe ich mein Projekt, dass bei BitBucket gehostet wird, auf den Git Flow umgestellt. Vorher war das eher Kraut und Rüben. Da ich ganz allein an dem Projekt arbeite ist, stellt mir meine Quellcode-Verwaltung das Branching Model als Linie dar, da nie Änderungen auf mehreren Zweigen erfolgen.
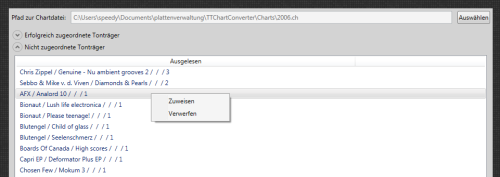
Ich begann ganz zaghaft mit einer Oberfläche, dann habe ich das Einlesen und Zerlegen der alten Charts-Dateien in Angriff genommen und diese dann über die Datenbankschnittstelle finden lassen. Dabei entstehen zwei Töpfchen: gefunden und nicht gefunden. "Nicht gefunden" kann heißen, dass ich die Bezeichnung geändert / verbessert habe oder die Platte verkauft wurde. Also gab es zwei Optionen: "Verwerfen" - das ging schnell und "Zuordnen" - das hat den Großteil der Zeit gekostet.
Für das Zuordnen musste ich erstmal jede Menge Komponenten, die ich schon für die "normale" Plattenverwaltung gebraucht habe und eine gemeinsam genutzte Komponente umziehen, Aufrufe korrigieren und dann konnte das Zuordnen beginnen. Nächste Hürde: Bisher hatte ich nie das permanente Wechseln zwischen zwei Screen (Übersicht und Suchmaske) in meinem Prozess. Die Datenbank rebellierte etwas, weil die Verbindung bereits geöffnet war oder der Garbage Collector sie mittendrin mal wegräumte.
Heute kam dann der letzte und entscheidende Schritt: Ich hatte alles soweit fertig, las die Datei ein, ordnete zu und lies mir nochmal die eingelesene Zeile und das zugeordnete Datenbankobjekt rausdumpen. Und irgendwie passte bei den manuell zugeordneten Sätzen zu Zuordnung nicht hin. Ursache war schnell gefunden: Die Charts basieren auf den einzelnen physischen Tonträger, die Suche für die Zuordnung aber auf den Veröffentlichungen. Klingt jetzt komisch, oder? Beispiel: Doppel-CD - die besteht aus zwei CDs, ist aber eine Veröffentlichung. Beides habe ich jetzt verwechselt. Jetzt musste ich nur schnell das komplette Programm mal kurz umbauen, damit sie Suche mit beiden Kriterien arbeiten kann und schon funktionierte alles.
 Das Anlegen war der nächste Punkt, den ich auf dem Plan hatte. Ich klebte erstmal alle Controls auf die Oberfläche, ordnete sie ein bisschen, sorgte für ein anständiges Databinding (Für Laien: Die Daten und die Oberfläche miteinander verknüpfen) und dann gingen die ersten Tests los. Hier klappte was mit der Aktualisierung nicht, da kollidierte der Datentyp mit der Darstellung. Kleine Problemchen, die ich alle mit einer Suchanfrage lösen konnte. Hin und wieder schon ich die Controls zurecht, bis ich so halbwegs zufrieden war. Es konnte der letzte und entscheidende Schritt folgen: Ersetzen der Dummy-Daten durch den richtigen Datenbankzugriff. Hier tat ich mich anfänglich schwer, aber als ich einmal den Rhythmus raus hatte, war auch die Datenbank zügig angebunden.
Das Anlegen war der nächste Punkt, den ich auf dem Plan hatte. Ich klebte erstmal alle Controls auf die Oberfläche, ordnete sie ein bisschen, sorgte für ein anständiges Databinding (Für Laien: Die Daten und die Oberfläche miteinander verknüpfen) und dann gingen die ersten Tests los. Hier klappte was mit der Aktualisierung nicht, da kollidierte der Datentyp mit der Darstellung. Kleine Problemchen, die ich alle mit einer Suchanfrage lösen konnte. Hin und wieder schon ich die Controls zurecht, bis ich so halbwegs zufrieden war. Es konnte der letzte und entscheidende Schritt folgen: Ersetzen der Dummy-Daten durch den richtigen Datenbankzugriff. Hier tat ich mich anfänglich schwer, aber als ich einmal den Rhythmus raus hatte, war auch die Datenbank zügig angebunden.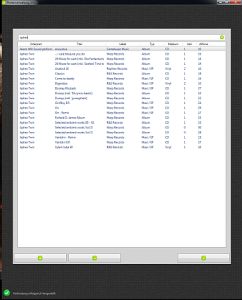 Der Test konnte weiter gehen - einzelne Platten als abgespielt markieren. Die Datenbankanbindung arbeitete fast perfekt - einmal wurden alle Platten geladen und dann wurde entsprechend dem Filter immer nur ein- und ausgeblendet. Markierte Platten wurden in eine extra Liste geschoben, die zum Schluss gespeichert wurde. Nur der Filter brachte mich zur Verzweiflung. Einmal gefiltert, wurde die Liste nie neu sortiert, sondern die vorher ausgeblendeten Platten wurde einfach wieder unten an die Liste angehängt. Also - neu sortieren nach jedem Filtern. Hatte ich mich im Filter vertippt und die Liste war dadurch leer, konnte ich den Suchbegriff entfernen oder was anderes Suchen - die Liste blieb leer. Mh, ein Aktualisierungsproblem, auch gelöst. Jetzt endlich konnte ich den Punkt ordentlich ausprobieren. Dumm war nur, dass mir die Fehler erst auffielen, als ich die Daten schon in die Datenbank geschrieben hatte. Äußerte sich dadurch, dass auch nicht gespielte Platten in der Liste befanden. Nachdem vermeintlich alles erledigt war, markierte ich, verließ dem Programmpunkt, wählte ich in wieder an, markierte weiter und hoppla... da waren noch die alten Elemente in der Liste. Bloß gut, dass ich das rechtzeitig gemerkt habe.
Der Test konnte weiter gehen - einzelne Platten als abgespielt markieren. Die Datenbankanbindung arbeitete fast perfekt - einmal wurden alle Platten geladen und dann wurde entsprechend dem Filter immer nur ein- und ausgeblendet. Markierte Platten wurden in eine extra Liste geschoben, die zum Schluss gespeichert wurde. Nur der Filter brachte mich zur Verzweiflung. Einmal gefiltert, wurde die Liste nie neu sortiert, sondern die vorher ausgeblendeten Platten wurde einfach wieder unten an die Liste angehängt. Also - neu sortieren nach jedem Filtern. Hatte ich mich im Filter vertippt und die Liste war dadurch leer, konnte ich den Suchbegriff entfernen oder was anderes Suchen - die Liste blieb leer. Mh, ein Aktualisierungsproblem, auch gelöst. Jetzt endlich konnte ich den Punkt ordentlich ausprobieren. Dumm war nur, dass mir die Fehler erst auffielen, als ich die Daten schon in die Datenbank geschrieben hatte. Äußerte sich dadurch, dass auch nicht gespielte Platten in der Liste befanden. Nachdem vermeintlich alles erledigt war, markierte ich, verließ dem Programmpunkt, wählte ich in wieder an, markierte weiter und hoppla... da waren noch die alten Elemente in der Liste. Bloß gut, dass ich das rechtzeitig gemerkt habe.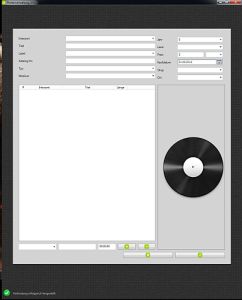 Anlegen entpuppte sich größtenteils als Fleißarbeit. Natürlich mussten jede Menge Daten geschrieben und gelesen werden, aber das ging sehr zügig von der Hand. Meine größte Sorge war ob das Framework die Verknüpfungen zwischen den Objekten gut hingekommt. Aber auch das lief sauber durch. Einzig die Persistierung (das dauerhafte Speichen der Daten) stellte sich quer, denn ich habe eine Verknüpfung zwischen der Platte und dem Interpreten bzw. dem einzelnen Titel und dem Interpreten. Das bescherte mir bei einer Single mit 2 Titeln drei mal den gleichen Interpreten als neue Datensätze. Als ich damit fertig war, konnte ich in den Praxistest gehen. Seither läuft das Programm in der Betaphase, d.h. ich starte es in der Entwicklungsumgebung und schaue immer mal auf die Daten, die so hin- und herhuschen.
Anlegen entpuppte sich größtenteils als Fleißarbeit. Natürlich mussten jede Menge Daten geschrieben und gelesen werden, aber das ging sehr zügig von der Hand. Meine größte Sorge war ob das Framework die Verknüpfungen zwischen den Objekten gut hingekommt. Aber auch das lief sauber durch. Einzig die Persistierung (das dauerhafte Speichen der Daten) stellte sich quer, denn ich habe eine Verknüpfung zwischen der Platte und dem Interpreten bzw. dem einzelnen Titel und dem Interpreten. Das bescherte mir bei einer Single mit 2 Titeln drei mal den gleichen Interpreten als neue Datensätze. Als ich damit fertig war, konnte ich in den Praxistest gehen. Seither läuft das Programm in der Betaphase, d.h. ich starte es in der Entwicklungsumgebung und schaue immer mal auf die Daten, die so hin- und herhuschen.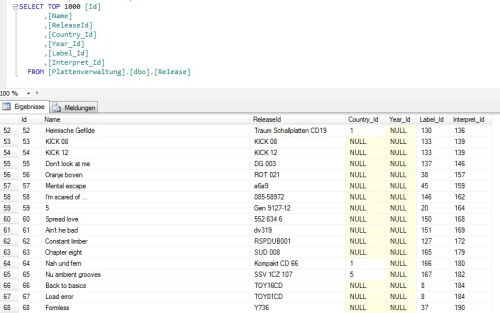

 Manche behaupten ja auch Programmieren sei eine Kunst und deshalb sind Programmierer auch immer ein Stück Künstler. Und um ein richtiger Künstler zu sein, benutzt man eine Sprache, in der man sich nicht nur logisch, sondern auch grafisch verausgaben kann -
Manche behaupten ja auch Programmieren sei eine Kunst und deshalb sind Programmierer auch immer ein Stück Künstler. Und um ein richtiger Künstler zu sein, benutzt man eine Sprache, in der man sich nicht nur logisch, sondern auch grafisch verausgaben kann -