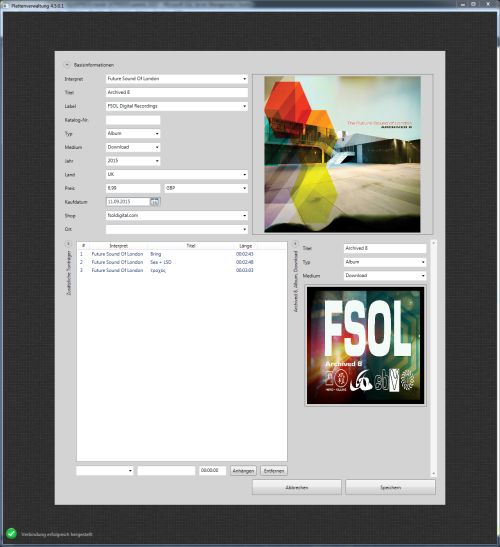
Heute geht es um Zweige und Quellcodeverwaltung. Der mitlesende Entwickler wird sich jetzt entspannt zurück lehnen und Bescheid wissen. Aber vielleicht ist es auch für Nicht-Entwickler mal interessant, wie so ein Entwickler es schafft, stabile Programme zu schreiben. Fangen wir mal mit der Quellcodeverwaltung an.
Falls uns mal die Bude abfackelt, lieben wir Entwickler es, wenn wir unseren Quellcode irgendwo ablegen können. Mit "abfackeln" meine ich das weniger im wörtlichen Sinne, sondern auch wenn wir merken, dass wir uns beim Entwickeln verrannt haben und zu einem sicheren Punkt zurück kehren müssen, wo wir wussten, dass die Version noch lief. Was passiert dann in so einer Quellcodeverwaltung? Es gibt immer das Original auf dem Server und eine lokale Kopie. Sobald wir die lokale Kopie verändern, wird das von der Quellcodeverwaltung registriert und die Datei wird als "In Bearbeitung" markiert. Ist man fertig mit seinen Änderungen, übergibt man der Quellcodeverwaltung seine Änderungen, wir sprechen dabei vom "Einchecken". Oder man stellt fest, dass der Ansatz schlecht war und verwirft seine Änderungen und stellt den Originalzustand wieder her.
Wenn das schon zu kompliziert war, kommt jetzt der Teil, wo ihr komplett aussteigt. Stellt euch vor, dass viele Entwickler an dem Quellcode arbeiten, dass es immer möglich sein muss, stabile Versionen auszuliefern und trotzdem neue Features dazu kommen sollen. Schauen wir doch also mal, wie ein Feature in eine Version kommt...
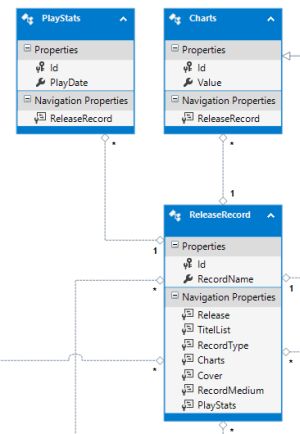
Auf der Grafik sieht man, dass parallel mehrere Versionsstränge existieren, als Entwickler reden wir von sogenannten Zweigen oder Branches. Wenn mir also eine neue Idee kommt, wie z.B. den Musikstil zu einer Platte zu hinterlegen, dann lege ich einen neuen Zweig an. Jetzt beginne ich in kleinen Häppchen das neue Feature zu entwickeln. Datenbankänderung, Schnittstelle zum Lesen / Schreiben erweitern, Daten lesen / schreiben, Oberfläche erweitern und alles verknüpfen - jede von diesen Aktionen ist unabhängig von einander und kann somit einzeln eingecheckt werden (das sind die kleinen lila Punkte).
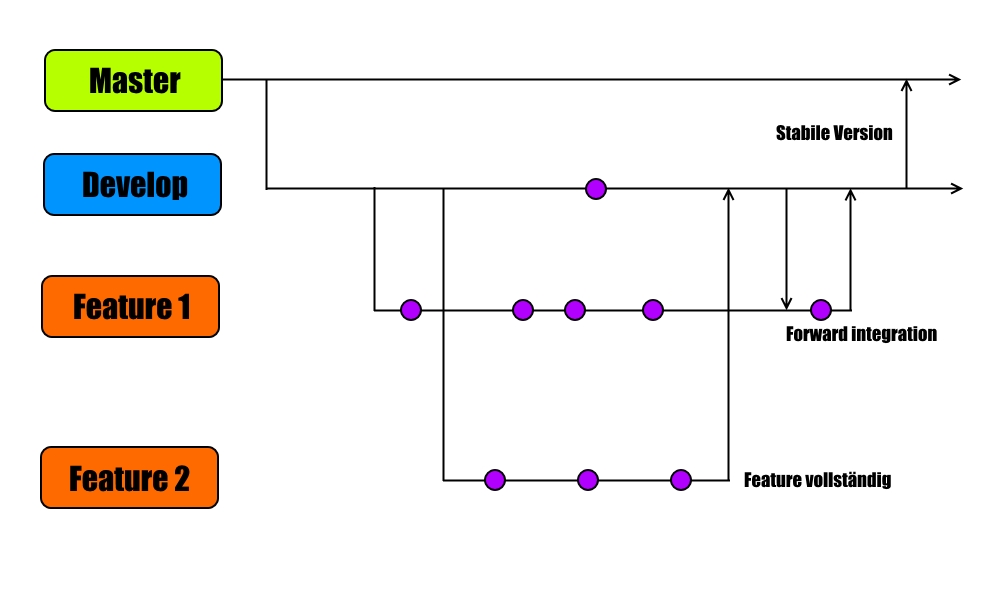
Wenn mir jetzt mittendrin noch ein neues Feature einfällt, dann erzeuge ich einen neuen Zweig, der auch auf der Develop-Version basiert. Da mache ich auch wieder ein paar Änderungen. Und beide Features werden unabhängig von einander entwickelt und ich kann sie beliebig lange offen halten, ohne irgend etwas zu gefährden. Jetzt bin ich mit dem zweiten Feature zuerst fertig - kein Problem, es wird in die Develop-Version übernommen und kann jetzt nochmal auf Herz und Nieren getestet werden.
Ich mache es immer so: Wenn ich ein neues Feature entwickle und teste, starte ich die Plattenverwaltung immer aus der Entwicklungsumgebung heraus. Sollte ein Absturz auftreten, bleibe ich sofort an der entsprechenden Stelle im Quellcode hängen und kann sie korrigieren. Läuft das neue Feature stabil, baue ich eine Version und arbeite ganz normal damit. Knallt es jetzt nochmal, dann ziehe ich das Verhalten in der Entwicklungsumgebung nach und korrigiere den Fehler in der Develop-Version. Ist dann auch hier alles in Ordnung, kommt jetzt das Feature von der Develop-Version in die Master-Version. Hier kommt wirklich nur das stabile Zeug rein. Dort wird auch nichts mehr geändert.
Was, wenn jetzt das nächste Feature fertig wird? Unter Umständen habe ich durch die zwei Features Änderungen an den selben Stellen im Quellcode gemacht und die passen nicht mehr zusammen. Damit würde der Develop-Zweig instabil werden. Ganz schlecht, denn hier sollen nur kleine Bugs gefixt werden. Also passiert was, dass wir "Forward Integration" nennen. Dafür gibt es kein schönes deutsches Wort. Es bedeutet, dass ich den Stand der Develop-Version (also mit Feature 2) in die Feature-Version übernehme. Jetzt wird alles korrigiert und stabilisiert, bis es passt und dann kann auch das neue Feature in die Develop-Version.
Ist ein Feature abgeschlossen, wird der entsprechende Zweig gelöscht, sobald er in der Develop-Version aufgegangen ist. Nur die Develop- und die Master-Zweige bleiben bestehen.
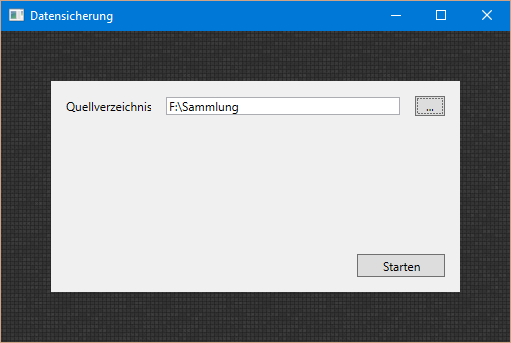
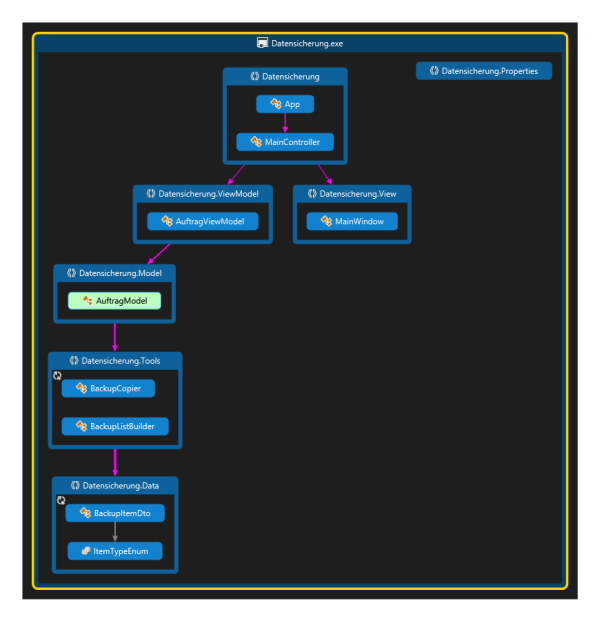
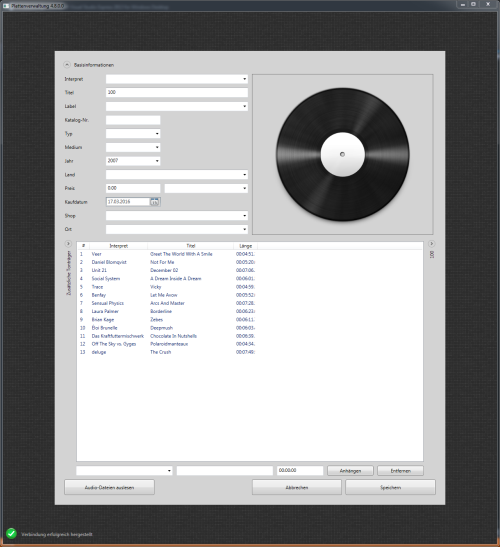 Klick auf den Button, Verzeichnis suchen und schon sind 13 Titel eingelesen[/caption]
Klick auf den Button, Verzeichnis suchen und schon sind 13 Titel eingelesen[/caption]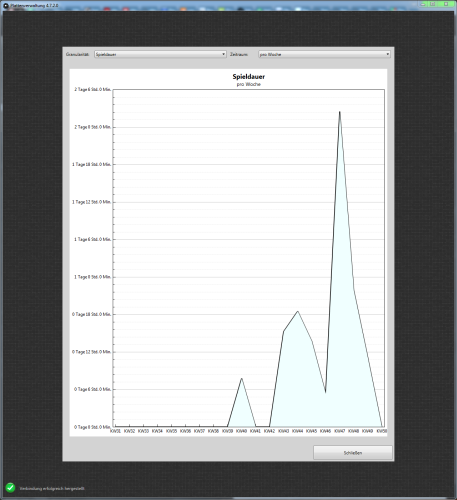 Von Zeit zu Zeit kam ich dazu, noch etwas Feintuning an meiner Statistik vorzunehmen. Es kamen viele Kleinigkeiten zusammen...
Von Zeit zu Zeit kam ich dazu, noch etwas Feintuning an meiner Statistik vorzunehmen. Es kamen viele Kleinigkeiten zusammen...
 Nachdem Apple beschlossen hat ihren iPod classic in die Schrottecke zu stellen und keinen Nachfolger außer ihre Touch-Serie in die Spur zu schicken, wird bei mir wohl über kurz oder lang ein anderer Player den iPod verdrängen. Und wenn der iPod erstmal weg ist, bröckelt das iTunes mit ihm weg und auch das Scrobbeln der Titel, die ich mit dem iPod abgespielt habe. Der gute alte WinAmp wird wieder ausgegraben und dafür sorgen, dass ich weiter Musik hören kann.
Nachdem Apple beschlossen hat ihren iPod classic in die Schrottecke zu stellen und keinen Nachfolger außer ihre Touch-Serie in die Spur zu schicken, wird bei mir wohl über kurz oder lang ein anderer Player den iPod verdrängen. Und wenn der iPod erstmal weg ist, bröckelt das iTunes mit ihm weg und auch das Scrobbeln der Titel, die ich mit dem iPod abgespielt habe. Der gute alte WinAmp wird wieder ausgegraben und dafür sorgen, dass ich weiter Musik hören kann.